
- 生成式艺术和算法创作01-概述
- 生成式艺术和算法创作02-随机和噪声
- 生成式艺术和算法创作03-混沌和分形
- 生成式艺术和算法创作04-规则系统
- 生成式艺术和算法创作05-Tessellation
- 生成式艺术和算法创作06-形状语法
- 生成式艺术和算法创作07-向自然致敬的 L-system
- 生成式艺术和算法创作08-马尔可夫模型
人工智能体
我们常看到 OOP - 面向对象的编程,对象是 Object。这篇文章则是关于智能体(agent)的综述。智能体和对象有什么区别呢?智能体是主动的,对象则不是。
智能体的概念是计算机科学的核心,在认知科学中也很重要。因为它可以研究真实的主体,建模和在现实世界中模拟并观察智能群体。
人工智能体是一个计算机系统,能够代表使用者或设计者自主运行。智能体可以形式化表达为从感知到行动的函数,它将每个可能的感知序列,映射到智能体可以执行的操作,或映射到影响最终操作的系数、反馈元素、函数或常量。软件和机器人都可视为智能体。
人工智能体有以下特征:
- 情境性(situatedness):通过传感器感知环境,能够通过行动效果器(effectors)影响环境
- 自主和积极主动(Autonomy and pro-activity): 行动没有外部干预,自己控制内部状态
- 灵活性
- 可响应: 及时响应环境的变化
- 社交性:与其他智能体或人类互动
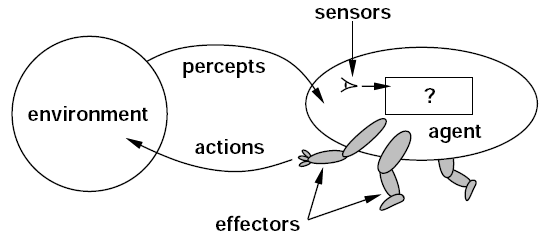
智能体的结构
- 认知(Cognitive):维持内部符号表征(一般会有记忆),可能包含推理和规划的评估结构(deliberative architectures)
- 反应(Reactive):没有明确的环境表征,专注于行为规则
- 反射:没有内部状态(只是将输入映射到输出)
- 反应:有内部状态(但不是认知)
- 混合(Hybrid):混合反应和认知成分,以平衡反应性(reactiveness)和审慎性(deliberativeness)
A first-order intentional system has beliefs and desires but no beliefs and desires about beliefs and desires.
A second -order intentioal system has beliefs and desires about beliefs and desires both those of others and its own.
一阶意向系统和二阶意向系统。
Belief–Desire–Intention BDI 模型
信念 - 愿望 - 意图模型(BDI)是智能体编程的软件模型。从表面看,它以智能体的信念、愿望和意图的实现为特征,使用这些概念来解决智能体编程中的特定问题。 实质上它提供了一种机制,将选择计划的活动与当前活动计划的执行分开。 因此,BDI 智能体能够平衡计划(选择做什么)和执行这些计划所花费的时间。

- Beliefs:信息态度,表示状态和智能体的 know-how,可能是错误的,由 perception 和 reasoning 更新
- Desires:动机态度,评估是对欲望的过滤,决定哪个愿望可以提升为真正的意图
- Intertions:智能体致力于发生的愿望,它是一致的、不冲突的、可能达成的,比 Desires 要强
确定性行动由以下元素表示:
- 可能包含参数的名称
- 前置条件列表:必须为真的要执行操作的事实列表
- 删除列表:执行操作后不再为真的事实列表
- 添加列表:通过执行操作使事实为真的列表

Interpreter 主要做两个操作:
- 根据当前的信念选择需要追求的意图
- Mean-end 推理生成或选择要执行的计划,以实现意图
BDI 算法可以表达如下:
1 | (B,D,I): = Initialize-state(); |
可以对基础 BDI 算法做很多调整,比如重新规划或意图再考虑。问题是,如果经常重新考虑,会花费太多时间来评估而没有足够时间采取行动;如果使用两种策略,不经常重新考虑,那么盲目执行可能会做出不相关的行动。
真是经典的 exploration vs. exploitation (deliberation and action) tension 呢!
智能体在多个创作领域的应用
UNMAKEABLE LOVE
UNMAKEABLE LOVE 是一个互动多媒体装置作品。此作品由多人操控,但观众无法操控 3D 动画影像,只能透过手电筒感应器的虚拟光束投射到背投式影幕,聚光探索 3D 人物动画的行为与影像。

作品中的六角形立体柱有六面背投式影幕,可由六个人同时操控手电筒聚光探索 3D 人物活动状况。当观众在操控手电筒投射屏幕观看时,会看到对面的观用者也在用手电筒投射,观看到的对方是真实人物经由红外线摄取影像呈现在屏幕,让观看者仿佛看到真实的另一观看者,让观看者之间在虚拟 3D人物动画的氛围情境内互动。
这个作品通过算法智能体,人工生命,虚拟社区,人机交互,增强虚拟,混合现实和多媒体表现的实践,以「参与身体的原始铭文」。它将 Beckett 的 “lost ones” 定位在一个虚拟空间中,这个虚拟空间代表着一种严重的身体限制状态,可能会唤起监狱,庇护,拘留营,甚至是「现实」的电视节目。
The Painting Fool
2013 年 7 月,一名崭露头角的艺术家在巴黎 Galerie Oberkampf 举办了展览会。
展览会持续了一周时间,民众前来观看,新闻媒体广泛报道,一些作品花了多年时间创作,还有一些直接画在画廊上。无论怎么看,这都是一场典型的艺术展。唯一不同的是,这名艺术家不是真人,而是一个名叫 The Painting Fool 的电脑程序。

The painting fool 是一个模块化的架构,包括:
- 视觉系统
- 内存模块
- 一些自我评价系统
- 感知系统
- 情绪系统
- 一些渲染模块,例如 肖像模块
- 解释系统
- 概念生成模块
The Painting Fool 是 Simon Colton 的作品。Colton 是伦敦大学金史密斯学院的计算机创作学教授,他认为要让程序创作,先要跨过一些与图灵测试不同的测试。图灵测试要求机器按人类的方式进行可以信服的交谈,Colton 却认为 AI 艺术家要让自己的行为变得「富有技巧」、「可以欣赏」、「富有想像力」才行。
到目前为止,Painting Fool 已经在这三个方面取得了进步。所谓的欣赏性,按 Colton 的意思就是对情绪作出反应。Painting Fool 的早期作品由图片拼成。程序先要扫描英国卫报一篇关于阿富汗战争的文章,从中提取关键字,比如“军队”和“英国人”,然后寻找与之相关的图片。找到之后程序用图片制作合成图,以反映报纸文章的内容和情绪。
音乐智能体
在音乐智能智能体方面,George E. Lewis 在 1983 完成了一个即兴的爵士演奏,是早期有智能智能体参与的例子:
George E. Lewis – Voyager Duo 4 - YouTube
Arne Eigenfeldt 是加拿大作曲家,他创作互动和生成音乐系统。 Eigenfeldt 为当代舞蹈做了大量工作,特别是与编舞家Serge Bennathan合作。他的电子音乐主要用 Max/MSP 编写的软件中实时生成。 他最近的研究重点是将知识编码到智能性能系统中。

Moments: Time and Space - YouTube
Music by agents 是 Arne Eigenfeldt 创建的实时作曲系统,由一组 BDI 智能体组成。智能体们协商各种参数,实现和谐的实时作曲。
James Maxwell, Arne Eigenfeldt, Philippe Pasquier开发的 MusiCOG 是一个用于单声道音乐信息的识别,生成,延续和模式编辑的系统模型。
Music composition is an intellectually demanding human activity that engages a wide range of cognitive faculties. In designing MusiCOG, we wanted to bring forward ideas from our previous work, and combine these with principles from the fields of music perception and cognition and ICA design, in an initial attempt at an integrated model.
为音乐理解和分类设计的 MusiCog 是认知智能体中,处理领域特定知识的智能体。音乐认知智能体一般会参与以下活动:
- 自己演奏
- 与人类一起演奏
- 帮助人类创作新材料
MUME 是一个汇集了对开发系统感兴趣的艺术家、从业者和研究人员的组织,研究可以自主地识别、学习、表现、编写、完成、陪伴或解释音乐的系统。Metacreation 涉及使用人工智能,人工生命和机器学习的工具和技术,它们本身通常受到认知和生命科学的启发。其中有一个项目叫做 Musebot。
![]()
Musebot 项目的目标是建立一个有趣和实验性的研究,教育和制作平台。它是一个协作性的创造性实验:共同制作自主软件智能体,共同制作原创音乐。这些软件智能体将在一个计算机网络上运行。每个软件智能体大致对应于一段音乐中的单个乐器部分,如贝斯或鼓点。
Musebot 可以与其他 Musebot 一起自动生成音乐。Musebot 协议传递实时数据,但不是具体数据,而是更高层次的音乐概念。
会话智能体,虚拟智能体,游戏智能体
会话智能体是相对成熟的智能智能体研究领域,一些典型的智能体包括:
ELIZA, Joseph Weizenbaum, 1964
PARRY, Kenneth Colby, 1972
SmarterChild, ActiveBuddy, 2001
Eugene Goostman, 2001
虚拟智能体
STELARC | PROSTHETIC HEAD (Stelarc, 2003) 是基于认知智能体体系结构的互动作品。智能体可以感知环境,通过检测颜色的超声波传感器来感知观众的服装颜色和基本的运动及行为:
游戏中存在许多认知智能体,它们通常不是游戏玩家,而是执行一些需要自动化的任务。这些互动叙事中的智能体行为,可能是预先编写好的,也可能是由程序自动生成的(比如 intelligent drama/story/manager 或 procedural simulation)。
智能体通信
认知智能体通过智能体消息和智能体通信协议进行交流,也可能使用 Agent communication language(ACL) 交流,常用的 ACL 有 KQML,FIPA ACL。
言语行为类型:
- 自信:speaker 表达世界表现(告知,断言,……)
- 指令:speaker 要求其他人(订单,问题,请求……)
- 承诺:speaker 承诺(承诺)
- 表达:speaker 表达感受(爱情宣言,…)
- 陈述:speaker 根据情境行事(开除,祝福,结婚……)
消息类型语义:言语行为,前提条件,后置条件。
智能体之间的通讯过程也涉及到复杂的感知、解释、推理、评估、行动等过程:

智能体通讯协议帮助结构化智能体之间的对话,提高通讯效率:

Ref
- Intelligent agent - Wikiwand
- Belief–desire–intention software model - Wikiwand
- Cognitive Agents And Multiagent Systems | Kadenze
- Musebot Getting Started | Musical Metacreation
- Topics in AI : AGENTS
- The Painting Fool - A Computer Artist
- Shadow agent: a new type of virtual agent
- music by agents – arne eigenfeldt
- MusiCOG & ManuScore |
- 40年认知架构研究概览:实现通用人工智能的道路上我们已走了多远? | 机器之心
- 机器学徒:AI有可能变成画家吗? | 雷锋网

